我們今天將會搭建我們開篇以來最複雜的 workflow,他的長相如下: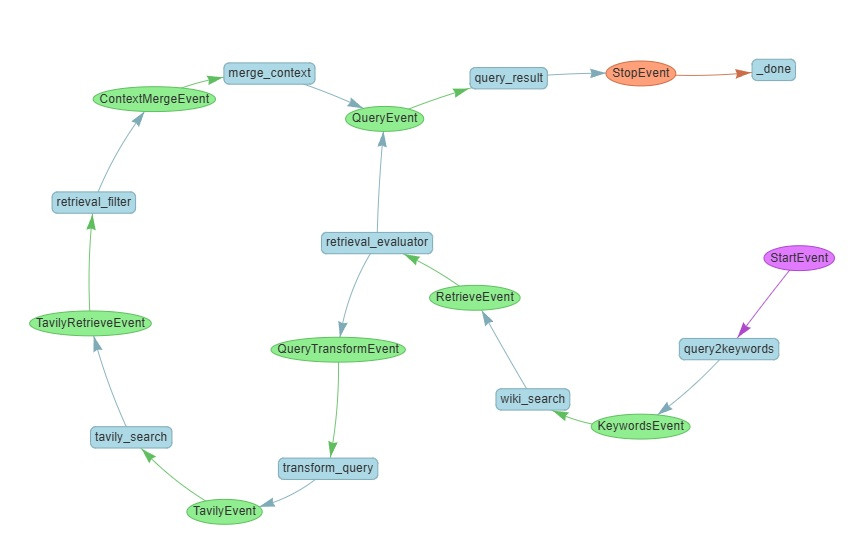
但實測後這個 workflow 的答題率仍然只有 7/10
究竟是怎麼回事,我們接著看吧
retrieval_evaluator 藍色長方形看起
釐清了核心之後,就剩下
query_result 分支,這邊就是普通的基於 context 來回答 query由於這邊內容比較多,我們捨棄了逐程式碼講解,轉而只討論關鍵步,完整實作可以在這裡找到
首先是 retrieval evaluator,這個和我們在 day26 做的事情一樣,我們只是把它重新包成 workflow 的一個 step
@step
async def retrieval_evaluator(self, ctx: Context, ev: RetrieveEvent) -> QueryEvent | QueryTransformEvent:
retrieved_nodes = ev.retrieved_nodes
context = make_context(retrieved_nodes)
query_str = await ctx.store.get("qset")
llm = self.llm
prompt = RETRIEVAL_EVALUATOR_PROMPT.format(query=query_str, context=context)
response = json.loads(llm.complete(prompt).text)
verdict = response['verdict']
feedback = response['feedback']
if verdict == 'correct':
return QueryEvent(query=query_str, context=context)
else:
return QueryTransformEvent(query=query_str, feedback=feedback)
'context 只詳述合谷穴的定位與功能,未提及「四關穴」或其與太衝等穴位的組合,缺少關鍵組成資訊。建議檢索「四關穴 組合/合谷 太衝」或查太衝穴資料以確認答案。'
@step
async def transform_query(self, ctx: Context, ev: QueryTransformEvent) -> TavilyEvent:
query = ev.query
feedback = ev.feedback
llm = self.llm
prompt = QUERY_TRANSFORM_PROMPT.format(query=query, feedback=feedback)
response = json.loads(llm.complete(prompt).text)
num_subqueries = len(response['refined_queries'])
await ctx.store.set("num_subqueries", num_subqueries)
return TavilyEvent(tavily_query=response['refined_queries'])
wf = CorrectiveRAGWorkflow(llm=mini, wiki_searcher=wiki_searcher)
refined_query = await wf.transform_query(ctx, evaluate_result)
refined_query
TavilyEvent(tavily_query=['四關穴 組成', '四關穴 包含哪些穴位', '合谷 太衝 是否構成 四關穴'])
@step
async def retrieval_filter(self, ctx: Context, ev: TavilyRetrieveEvent) -> ContextMergeEvent:
retrieved_result = ev.retrieved_nodes
llm = self.llm
rvs = []
for idx, item in enumerate(retrieved_result):
print(f"{idx}", end=', ')
sub_query, doc = item
text = doc.text
prompt = DOCUMENT_EXTRACT_PROMPT.format(query=sub_query, document=text)
response = json.loads(llm.complete(prompt).text)
rvs.append((response, sub_query, doc))
return ContextMergeEvent(retrieved_nodes=rvs)
DOCUMENT_EXTRACT_PROMPT = PromptTemplate(
template="""你是精準的文本抽取器。你的任務有兩個:
1. 判定下面的 DOCUMENT 是否應保留作為 QUERY 的候選 context。
2. 如果保留,抽取最能直接回答 QUERY 的句子(1-3 句)。
條件:
- 只摘自原文(不要改寫或新增資訊)。
- 優先保留直接回答 QUERY 或含關鍵詞的句子。
- 若 DOCUMENT 與 QUERY 明顯無關、是廣告、重複或空白,回 keep=false。
- 嚴格輸出 JSON 格式,不要多餘文字。
輸出 JSON schema:
{
"keep": true|false, # 是否保留 DOCUMENT
"reason": "一句話說明為何保留或捨棄",
"important_spans": [ # 若保留,列出 0~3 個最關鍵短句
"片段內容1", "片段內容2", "片段內容3"
]
}
輸入:
QUERY: {query}
DOCUMENT: {document}
"""
)
我們在 10 題的測試裡,gemma 從 答對 7 題 持平仍然為 答對 7 題
這是我們的 context relevancy vs Faithfulness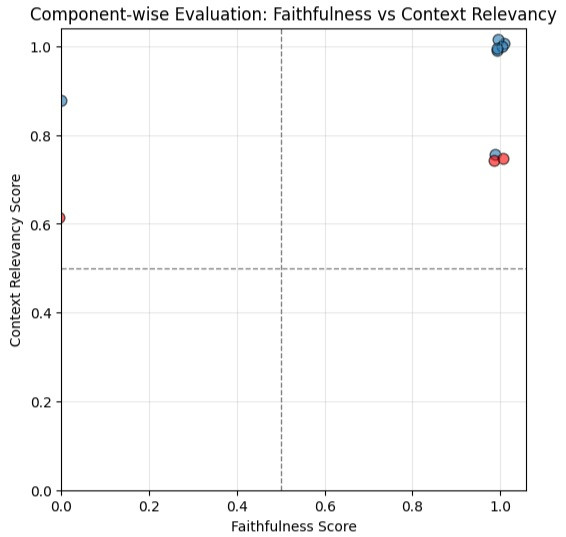
從圖上我們可以看到,有不少點的 context relevancy 分數掉到 0.8 以下,這個 0.8 的占比包含:
關於 Faithfulness 掉到 0 的題目:
兩題都是屬於模型為了回答問題而自行產生了不存在於 context 的內容
這部分我覺得是因為我們的 context 已經變得比較精簡了,所以使得我們的 Faithfulness 看起來更 work
最後是我們以 問題的 index 為 x 軸的答題情況: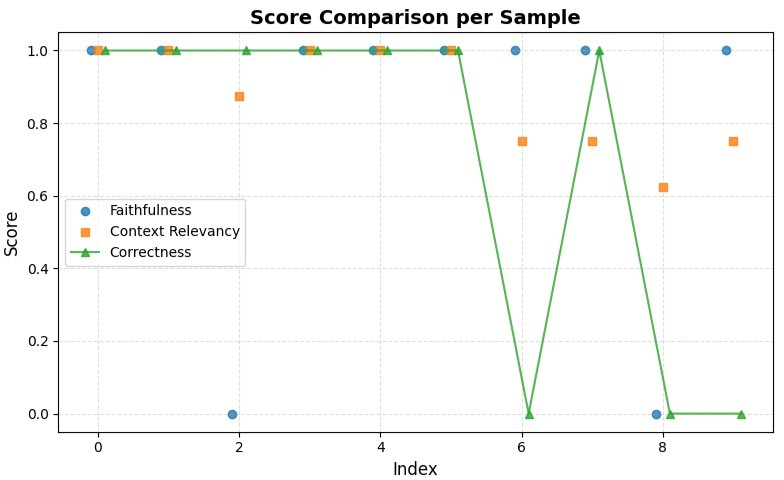
我們這次看到,答錯的題目主要都伴隨了 context relevancy 沒有滿分
下列敘述共幾項正確 這種無法單靠兩次檢索就可以答對

 iThome鐵人賽
iThome鐵人賽